

Machine Learning Guides Peptide Nucleic Acid Flow Synthesis and Sequence Design
Machine Learning Guides Peptide Nucleic Acid Flow Synthesis and Sequence Design
Advanced Science Volume9, Issue34 December 8, 2022 - 2201988
Chengxi Li, Genwei Zhang, Somesh Mohapatra, Alex J. Callahan, Andrei Loas, Rafael Gómez-Bombarelli, Bradley L. Pentelute
Abstract
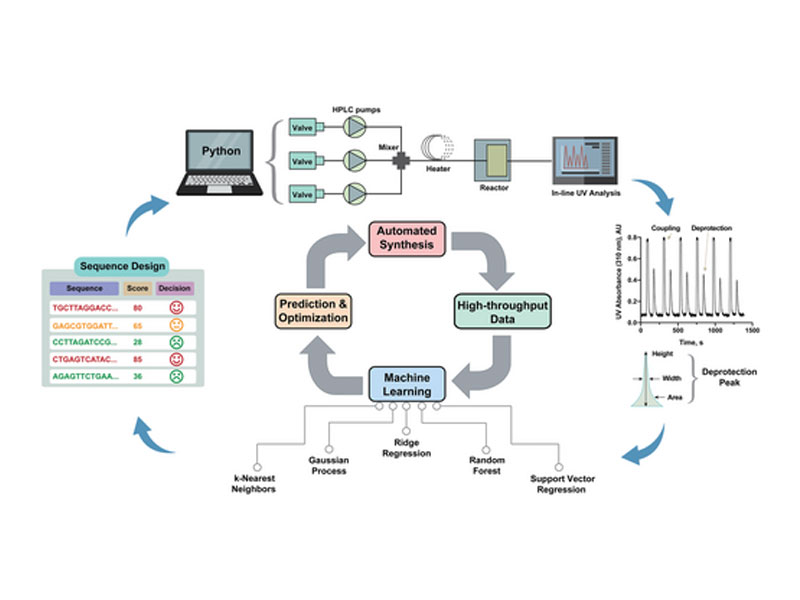
Peptide nucleic acids (PNAs) are potential antisense therapies for genetic, acquired, and viral diseases. Efficiently selecting candidate PNA sequences for synthesis and evaluation from a genome containing hundreds to thousands of options can be challenging. To facilitate this process, this work leverages machine learning (ML) algorithms and automated synthesis technology to predict PNA synthesis efficiency and guide rational PNA sequence design. The training data is collected from individual fluorenylmethyloxycarbonyl (Fmoc) deprotection reactions performed on a fully automated PNA synthesizer. The optimized ML model allows for 93% prediction accuracy and 0.97 Pearson's r. The predicted synthesis scores are validated to be correlated with the experimental high-performance liquid chromatography (HPLC) crude purities (correlation coefficient R2 = 0.95). Furthermore, a general applicability of ML is demonstrated through designing synthetically accessible antisense PNA sequences from 102 315 predicted candidates targeting exon 44 of the human dystrophin gene, SARS-CoV-2, HIV, as well as selected genes associated with cardiovascular diseases, type II diabetes, and various cancers. Collectively, ML provides an accurate prediction of PNA synthesis quality and serves as a useful computational tool for informing PNA sequence design.